
Stable Diffusion Web UIのインストール方法をご紹介しました。
本記事では基本的な用語や知識についてご紹介していきます。
基本的な画面構成
text2imageの画面を使用して、基本的な画面と用語の解説をします。
それぞれ簡単に解説していきますので、より細かい解説は別途、記事にしたいと思います。
▼text2image
▼text2imageの構成要素
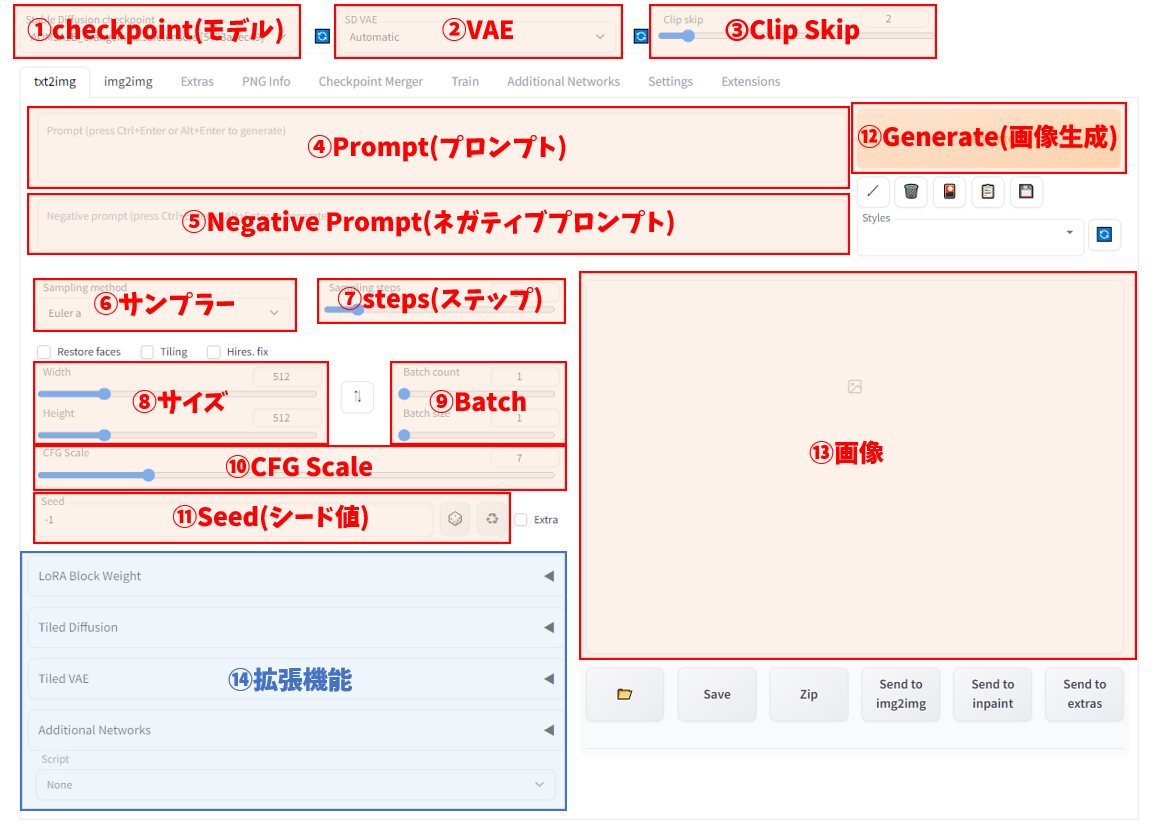
①checkpoint(モデル)
WebUI自体は画像生成ができず、大量のデータから学習した学習モデルとセットで初めて画像を生成することができます。
学習モデルには、美少女イラストに特化したモデルや実写のようなリアルに特化したモデル、風景に特化したモデルなど、学習させたデータセットによってさまざまな特徴を持っています。
モデルは、「.ckpt」と「.safetensors」の2つの拡張子があり最近は「.safetensors」がメインに使われております。以前は「.ckpt」が主流でしたが、データ量が多く重たい、かつ悪意あるデータを組み込めてしまう可能性がありました。「.safetensors」は、データ量を軽くすることができ、悪意あるデータを入れることが非常に困難になった拡張子です。直近に作成されたモデルが「.ckpt」であることは少なくなりましたが、念のため確認する癖付けをしておくのが無難です。
②VAE
ざっくり生成された画像のクオリティが上がるもの程度の認識で問題ありません。(ベテランでも仕組みが理解できてない人が多い。なんなら私もよくわかってない)
モデル自体に組み込んでVAEの設定が不要なモデルもあります。モデルをダウンロードする際はVAE内臓モデルか、もしくは推奨VAEがあるかを併せて確認するようにしましょう。
➂Clip Skip
少し難しい話になりますが、画像生成AIは11個にLayerが分かれておりそれぞれのLayerに担当があります。使わないLayer数の設定ができます。
最初はとりあえず「1」のままでOKです。他の機能に慣れて余裕ができましたら他の数字を試してみると面白いと思います。
④Prompt(プロンプト)
t2iにおいて最も重要な要素の1つです。プロンプトに記載された指示文に元に画像を生成します。
英単語を「,」で区切って、盛り込みたい要素を並べるだけで基本的にOKですが、モデルによって苦手な構図やそもそも画像生成AI自体が苦手な要素もあったりします。色々試して自分なりのコツを見つけていきましょう。
始めにクオリティ関連のプロンプトを入力し、「どんな人がどこで何をしているか?」を追加しましょう。またさまざまなAI画像投稿サイトにてプロンプトの公開がされています。先輩たちのプロンプトを参考にしてみましょう。
⑤Negative Prompt(ネガティブプロンプト)
「盛り込みたい要素」をプロンプトで入力するのに対し、ネガティブプロンプトは「盛り込みたくない要素」を入力する欄です。
例えば、worst quality,low qualityなどと低クオリティをネガティブプロンプトに入力することで、高クオリティなイラストを生成してくれます。
⑥サンプラー
AIがノイズ処理をするアルゴリズムのことを指します。いろいろな種類があり、同じモデルとシード値でもサンプラーを変更すると雰囲気が大きく変わったり、書き込み量に変化があったりします。
人気なサンプラーは「DPM++ 2M Karras」で、多少の負荷に耐えられる環境であれば「DPM++ SDE Karras」が挙げられると思います。
⑦steps(ステップ)
ステップはAIがノイズを取り除く作業の反復回数のことを指します。低ステップではノイズを取り切れずぼんやりした画像になってしまいます。
20ステップ程度であれば大体ノイズ除去できますので、目安にしてみてください。
モデルにもよりますが、一概に高いステップにすれば高クオリティになるわけではないですし、高ステップほどPC負荷も高まりますので環境とモデルに合わせて加減しましょう。
⑧サイズ
生成する画像のサイズ。大きい画像ほどGPUを使用し負荷が高まるので、PCスペックによってはメモリ不足でエラーとなることがあります。
UpScalerやHires fixを用いれば拡大できますので、大き目の画像を生成したいときはそちらで拡大しましょう。
また、「Tiled Diffusion」という拡張機能を使って非常に大きな画像も作ることができるようになりました。ここのサイズは最低限にし、拡大機能で大きな画像にする流れが良いと思います。
⑨Batch
生成する画像の数の設定ができます。
Batch count:生成する回数
Batch size:同時に生成する画像数
つまりcount:3、size:4であれば、4枚同時生成を3回行うになります。
同時生成はPCスペックが求められますので通常はsizeを1で、生成した枚数をcountに入力することが多いと思います。
なお、Generateを右クリックするとGenerate foreverが選択でき、キャンセルするまでずっと生成し続けてくれる機能もあります。止めるときはもう1度Generateを右クリックして、Cancel Generate foreverをクリックしてください。
⑩CFG Scale
簡単に言うと「プロンプトの再現度」です。AIがプロンプトの内容をどこまで厳密に再現するかを設定できます。大抵の学習モデルには推奨スケール値が案内されていますので、参考にして調整してみましょう。
傾向として、低スケールだと柔らかい雰囲気だがぼんやりしていて、高スケールだとパキっとした雰囲気だが崩壊しやすくなります。目安は7~9くらいです。
⑪Seed(シード値)
画像生成AIがノイズの取り除き方の乱数に設定値が割り振られています。このシード値が異なると違う画像が生成され、同じシード値であれば同じ画像が生成されます。
この機能を使って、過去に生成した画像を再び生成したり、他人が生成した画像と同じものを生成したりすることができます。
初期値の「-1」はこのシード値を毎回ランダムにするためです。
⑫Generate(画像生成)
画像生成を開始するボタン。右クリックするとGenerate foreverが選択でき、キャンセルするまでずっと生成し続けてくれる。
⑬画像
生成した画像を表示する欄。ここから直接右クリックで保存もできるし、i2iやextrasへ送ることもできる。
⑭拡張機能
様々な拡張機能の設定ができる。今回は割愛。
広告
終わりに
画面を用いて、基本的な用語の簡単な解説でした。覚えることが多く大変そうに見えますが、実際に少し触ってみれば、わかる部分も多いと思います。
また、なんとなくこの設定にしている箇所があったりすることは少なくないです。全部を完璧にしようとせず、楽しみましょう!